Back in 2008 the future of the public cloud looked like it was limitless. Public cloud providers planned to eventually assimilate all on-premises data and workloads. Resistance to the public cloud was perceived to be futile. Ten years later a nascent rebellion among cloud consumers is rejecting the public cloud. The movement to repatriate data and workloads to on-premises infrastructure is underway.
So what is driving the repatriation of data and workloads from the public cloud? The drivers include rising costs, lack of physical control, security breaches, service outages, and performance issues. Public cloud consumers are finding that private clouds as well as deployments on bare metal with or without virtualization are better choices for them than the public cloud.
What is the public cloud response to customer repatriation of data and workloads? The public cloud is mutating to provide hybrid cloud services. AWS, which historically opposed offering hybrid cloud services, announced at AWS re:Invent 2018, that AWS Outposts will offer a partial stack of AWS services for hybrid clouds in private data centers. VMware, which was part of the AWS Outposts announcement already offers a hybrid cloud service using purpose built infrastructure at AWS. Google has been low-key about hybrid cloud, but it does offer the Google Kubernetes Engine (GKE) on premises for application developers.
Microsoft has delivered its Azure Stack services on-premises using a Reference Architecture (RA) that can be obtained from Cisco, Dell EMC, HPE, and Lenovo. Azure Stack can be operated as a hybrid cloud with the Azure public cloud or as a private cloud not connected to Microsoft Azure.
IBM Cloud Private and the recently announced acquisition of Red Hat gives IBM on-premises and hybrid cloud solutions for their customers which will work with IBM's public cloud services. Although IBM has a relatively small footprint in the public cloud, owning Red Hat will permit IBM to compete with Microsoft's on-premises private and hybrid Azure Stack.
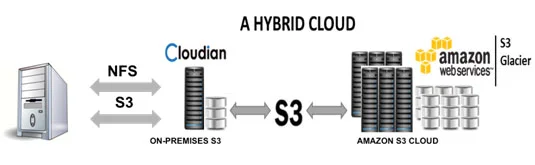
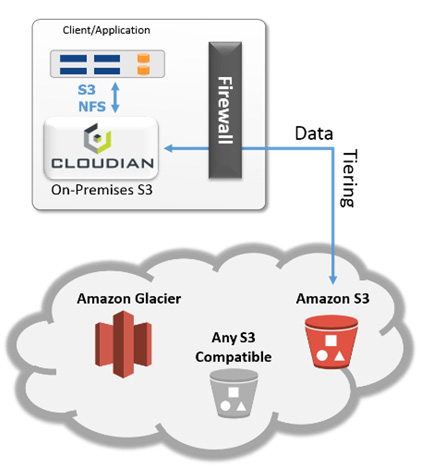
The known unknown is whether the public cloud with its no capex consumption model can be replicated in private, hybrid, and community clouds. The proof of concept could come from Cloudian, which provides software for S3-compatible object storage clusters, and Pure Storage, which offers all-flash arrays for enterprise data storage. Both companies are developing an on-premises storage consumption model with no customer capex.
If the public cloud consumption model can be replicated in private, hybrid, and community clouds, then the question is where will it be preferable to consume your computing services? The answer is starting to emerge with data and workload repatriation from the public cloud. Hybrid cloud adoption is almost sure to increase with the entry of AWS. Private and community clouds based on a no capex consumption model will have a bright future as more customers choose non-public cloud alternatives.
The public cloud was conceived as a pay for what you use web-scale computing environment, but it does not have a monopoly on the features and benefits of cloud computing. Resistance is not futile. Bring your data and workloads home.
MonadCloud builds private cloud and community cloud storage in New England using Cloudian HyperStore software and Lenovo storage servers.